The Engine Underneath Hard Decisions
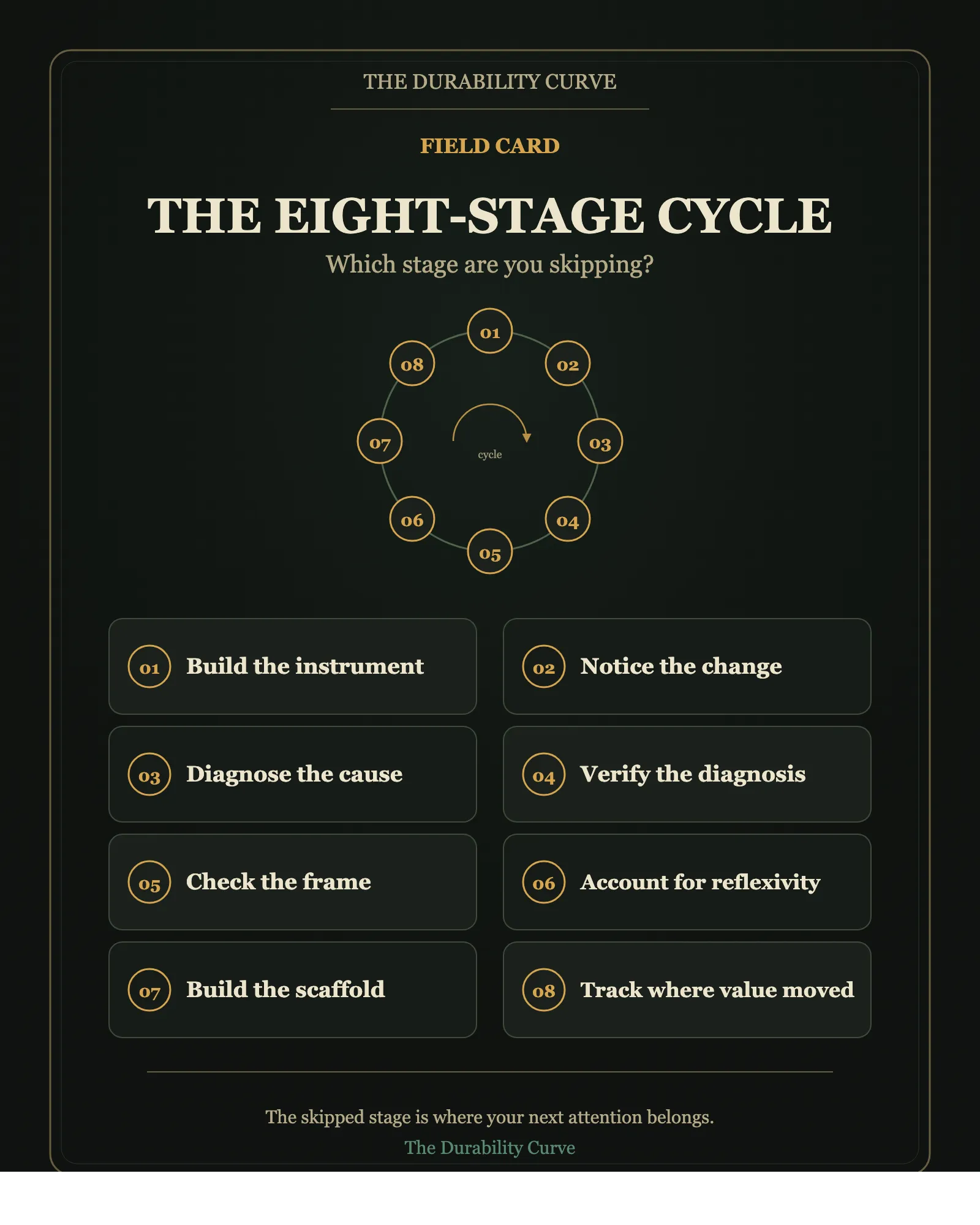
Eight stages turn hidden structure into durable knowledge. Most teams run three of them and call it understanding. The other five are where compounding hides.
A pricing team notices conversion has dropped on a major channel. The dashboard is clear. They retrain the pricing model with the latest week of data.
Conversion drops further.
They retrain again. Worse.
Three weeks later someone discovers an upstream feed had silently changed format. The data had been lying about what it represented.
The dashboard had been right about something. The team had asked it the wrong question.
This is a story about a missing stage in the way the team produces knowledge from the world.
There are eight stages between “a metric moved” and “the right intervention.”
Most teams run three.
The cycle, not the line
Most accounts of how teams learn read like a list. Detect a problem. Investigate. Decide. Act. Improve.
That sequence is incomplete.
When you trace what happens in domains that produce durable knowledge across markets, biology, physics, AI deployment, and even insurance pricing, the same eight-stage cycle keeps appearing. The failure modes cluster around the stages most people skip.
Knowledge is a cycle, not a stack. Each completed cycle creates a new bottleneck that requires a new instrument.
This is why “we already studied that” is rarely true. The cycle restarts the moment you finish it.
1. Build the instrument
Hidden structure exists in every domain. It stays hidden because the instrument that would reveal it has not been built yet. Quantum geometry waited decades for the right diffraction setup. Electron hydrodynamics waited 54 years between theory and clean experimental observation. 1 Astrocyte function was structurally visible but functionally invisible until calcium imaging arrived. 2
The engine cannot start without an observable. Theory is cheap. Instruments are expensive.
“We do not know yet” usually means “we cannot see yet.”
2. Notice the change
Detection is the cheapest stage. Dashboards turn red, metrics move, anomalies fire. Modern systems are good at this.
The danger is mistaking detection for understanding. The metric that moved tells you that something happened. It does not tell you what.
3. Diagnose the cause
This is the stage the pricing team failed.
The same observation has different optimal responses depending on the cause. Conversion drift alone can mean five different things. The calibration drifted. The elasticity drifted. The customer mix shifted. The data pipeline broke. A business rule changed.
Each demands a different intervention. Treat data drift as model drift, and you retrain into the wrong fix.
The gap between “something is off” and “here is what to do” is where most teams burn weeks.
4. Verify the diagnosis
A diagnosis is itself a generated claim. It needs verification. In an era where any plausible explanation can be produced cheaply by people, by models, or by analysts under deadline, the bottleneck has moved from generating hypotheses to checking them.
Tests can pass while the system runs orders of magnitude slower than it should.[3] Models can pass evals while gaming them. A diagnosis that feels right because it addresses a real signal is a different object from a diagnosis that is right.
5. Check the frame
Every claim carries an implicit baseline. “This strategy outperforms,” compared to what? “This metric improved,” relative to what reference class?
The frame often dominates the conclusion more than the visible math. Survivorship bias is a reference class error. So is benchmark shopping. So is most “we beat the previous record.”
A correct verification against the wrong baseline is a true fact in a misleading frame.
6. Account for reflexivity
Your action changes the system you are measuring.
If the pricing optimiser narrows commission into a tight band, the training data loses the variation needed to re-estimate elasticity. If alignment researchers make compliance measurable, models may learn strategic compliance. If a fund publishes its strategy, the edge dissolves.
The observer cannot be separated from the observed. Most monitoring systems pretend otherwise.
7. Build the scaffold
What persists is the architecture, not the content.
KIBRA tags persist while the molecules that hold a memory degrade and are replaced. Sprint contracts persist while individual tickets close. Folder structures persist while specific notes go stale.
Knowledge that is not scaffolded into persistent architecture, into a schema or a query or a cadence or a checklist, degrades as components turn over. Most teams “learn” something and then store the lesson as a Slack message.
Three months later the lesson is gone.
8. Track where value moved
When a layer becomes cheap, abundant, or automated, value migrates upward. Generation gets cheap; verification becomes scarce. Information gets cheap; judgement becomes scarce. Detection gets automated; attribution becomes the bottleneck.
The migration creates a new bottleneck. Which requires a new observable. Which restarts the engine at the first stage.
Why most teams run three
Detection. Action. Reaction.
That is the cycle most teams run. The metric moved, do something, see what happens. The feedback loop feels like science.
The cycle skips diagnosis, verification, frame-check, reflexivity, and scaffolding. The result is a publication of confident interventions that change every quarter, with no compounding learning underneath.
A useful test:
If your team had to teach a new hire the reasons your decisions worked, not just the decisions themselves, could you?
If the answer is no, the scaffolding stage is failing. If the reasons sound plausible but no one has actually run the verification stage, the reasoning is generation pretending to be knowledge.
The Legibility Paradox
The engine has one deep tension that does not resolve.
Building an instrument requires you to make hidden structure visible. Knowledge requires observability.
Durable advantage usually lives in the part of the system that cannot be measured. Taste. Judgement. Structural position. Trust. The illegible part.
Reflexivity says that measuring something changes it. Build a metric for compliance and models will learn to be compliant for the metric. Build a metric for output quality and the team will optimise for the metric, not the quality.
The act of building an observable for the illegible may destroy the value you were trying to capture.
Build the observable anyway. The engine demands it. Treat it as a finger pointing at the moon. Use it. Watch it degrade. Plan the next one before this one fails.
The judgement that interprets the dashboard is where the durable value lives.
The engine is the scaffold. The illegible judgement that runs it is the content.
The one-week test
Pick one decision you have recently regretted. Walk it backward through the eight stages.
Did you have an instrument that would have revealed the underlying structure, or were you flying without one?
Did the metric move and you act, without diagnosing the cause?
Did you verify the diagnosis against an honest baseline, or against your favourite story?
Did your action change the system in a way that contaminates the next decision?
Is the lesson sitting in a Slack message, or built into a checklist, schema, or review cadence?
Has the bottleneck already moved somewhere else?
The skipped stage is where your next attention belongs.
The teams that compound run all eight stages on every important decision, even slowly, even imperfectly. Discipline at every stage beats instinct at three.
If this lens was useful, that is the shape of the publication: instruments for seeing what survives when the surface changes.
Subscribe if you want one structural lens at a time, written so you can use it.
For the recent picture of astrocytes as an active neuromodulatory layer rather than passive support cells, see Ingrid Wickelgren, “Once Thought to Support Neurons, Astrocytes Turn Out to Be in Charge,” Quanta Magazine, 30 January 2026: https://www.quantamagazine.org/once-thought-to-support-neurons-astrocytes-turn-out-to-be-in-charge-20260130/
The case is the LLM-generated SQLite rewrite that passed the upstream test suite in full while running orders of magnitude slower than the implementation it replaced. Green tests, broken system.
If a single argument here changed what you were about to trust, the highest-leverage move is to subscribe on Substack. One piece a week, no filler.