Prompting Isn't Writing, It's Compilation
If you treat the prompt as a spec and the model as a renderer, quality stops coming from more words and starts coming from better constraints.
I keep reading prompt tips that assume the way to get better output is to write more.
More adjectives. More moodboard language. More camera jargon. More cinematic this, ethereal that.
The working assumption is that a prompt is an essay, and a good prompt is a well-written essay. So people iterate on the sentence. They swap in fancier words. They add qualifiers. They layer on references.
Most of the time, the output does not get better. It just gets noisier.
The mistake is upstream of the writing.
A prompt is not an essay. It is a specification.
And once you see it that way, the job changes completely.
The Prompt And The Spec
A spec is not judged by how it reads. It is judged by whether the thing it asks for can be produced reliably.
That is a very different discipline.
When you write an essay, you add words to make a point clearer. When you write a spec, you remove options to make an outcome reproducible.
In image generation, most of the real quality lives inside a small set of non-obvious decisions. What kind of image is this actually for. What must stay true across every seed. What is free to vary. What the camera is doing. What the aspect ratio is. How much stylisation to allow. What to explicitly exclude.
Those are not adjective choices. They are constraint choices.
And constraints are not prose.
They are parameters in a program the model runs.
If you accept that framing, the writing part of prompting quietly stops being the interesting part.
The interesting part is the compiler that turns small input into the right constrained program.
What This Looks Like In Practice
I built one of these for Midjourney. It is small, deterministic, and boring in the way good tools are boring.
You give it a tiny input. Just enough to know what you want. A subject. Optionally, the asset job.
The compiler does the rest.
It routes your input to one of about ten regimes. Cover art. Thumbnail. Vertical poster. Blog header. Product photo. Portrait. Concept art. Logo. UI mockup. Texture.
Each regime carries its own defaults. A product photo wants a square crop, low stylisation, low chaos, camera-and-material language, and realistic lighting. A concept art prompt wants a widescreen crop, more stylisation, room for exploration, and strong atmosphere. A logo wants the opposite: square, very low stylisation, strong exclusions against mockup and render cues. A UI mockup wants layout language first and aesthetic language last.
Nobody reading a single prompt could see all of that. It is not in the sentence. It is in the spec the compiler is quietly loading behind it.
Once the regime is chosen, the compiler fills the constraint stack in a fixed order. Subject. Framing. Environment. Style anchor. Palette. Exclusions. Then it attaches the parameter policy for that regime. Aspect ratio. Stylise. Chaos. Model version. Negative flags.
The output is a prompt, yes. But the prompt is a side-effect.
The real product is the decision about which levers to move at all.
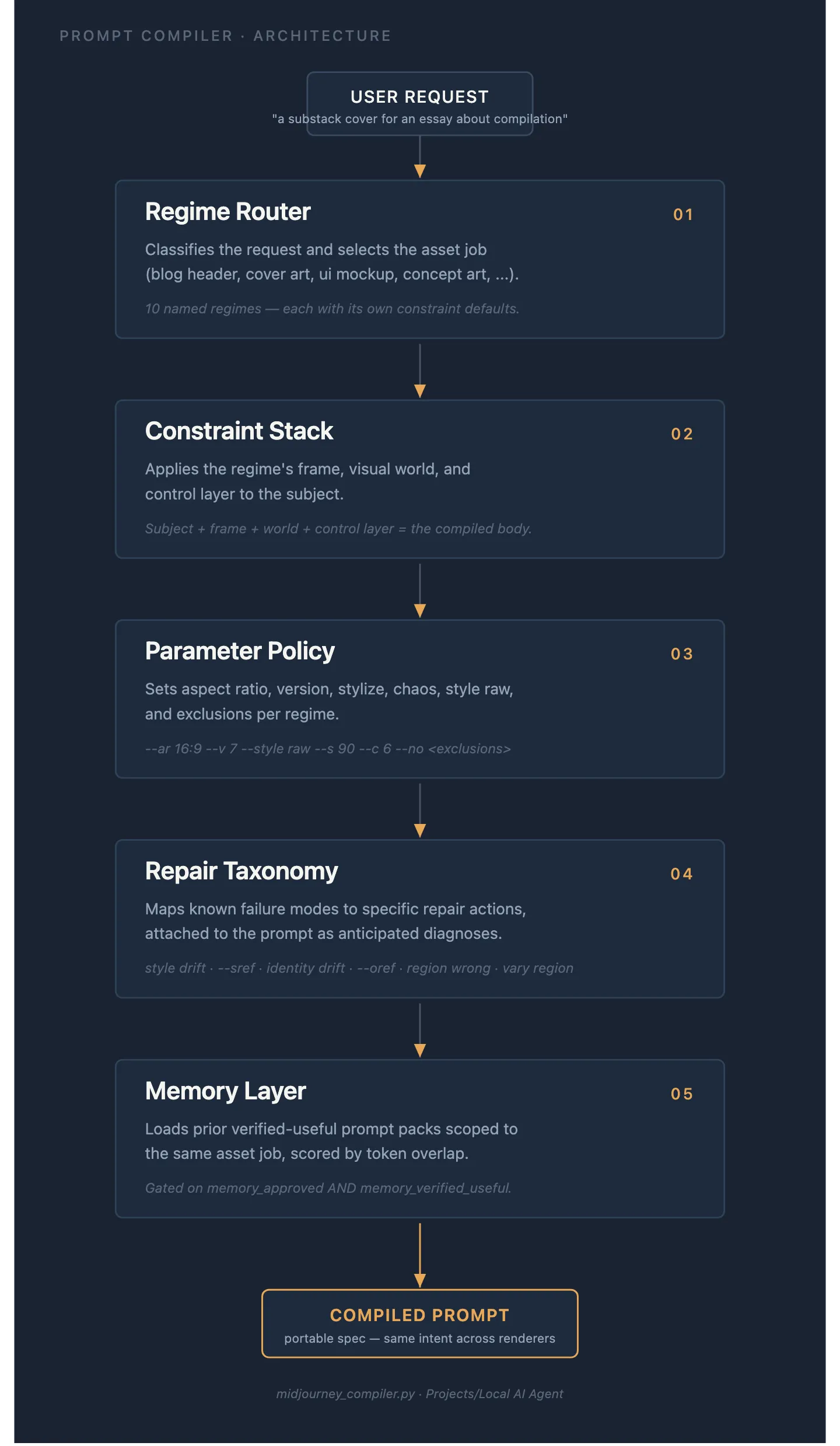
The five layers a working prompt compiler actually has. None of them live in the prompt text.
A compiled prompt looks like this:
A vault knowledge concept-art image, dramatic atmospheric lighting,
a lone reader at the centre of a cathedral of interlinked pages,
small-temple scale, painterly cinematic style,
deep navy palette with warm gold highlights
--ar 16:9 --stylize 180 --chaos 12 --v 7
--no text, ui, watermarkConcept-art regime. Subject, frame, world, style anchor, palette, exclusions, parameter policy. Six lines. Every line is a decision the compiler made before any text was written. The “writing” part took about thirty seconds because by that point the only live choices were the subject and the palette.
Most of the work happened upstream of the sentence.
Repair Beats First-Pass
Here is the part most prompt writing misses.
The first render is not where quality lives.
Quality lives in how you respond when the first render is wrong.
When a prompt fails, people usually rewrite the whole thing. They replace adjectives. They try a different mood. They add three more reference artists. They change everything at once and learn nothing from the result.
A compiler does not do that.
A compiler classifies the failure and applies one known correction.
If the composition is wrong, it changes the framing term and leaves everything else alone. If the style is drifting, it strengthens the style anchor. If the output is too random, it drops the chaos parameter. If the output is too bland, it nudges stylisation up by one step. If a logo comes back looking like an illustration, it adds the vector and symbol constraints that logos always need.
These are not clever hacks. They are rules.
The moment you can name the failure, you know which lever to move.
And you move one lever at a time, so every iteration actually tells you something.
The difference between random-walking through adjectives and compiling-then-repairing is not subtle. One drifts. The other converges.
The Moat Isn’t The Prompt Text
This is the part I keep wanting to tell people who are trying to build an edge with image generation.
The prompt text does not matter.
Anyone can prompt. Anyone can paste a screenshot of someone else’s output and ask a model to reverse-engineer the sentence. Prompts are, by design, the most copyable thing in the workflow.
The constraint library is not.
The tasteful defaults are not. The boundary between regimes is not. The repair taxonomy is not. The style packs you have curated and stress-tested are not. The library of bundles you have actually verified produce work you would ship: which constraint stack, which aspect ratio, which style reference, all flagged useful by your own eye.
That is the moat. It is the scaffold, not the content.
It is also invisible from the outside. You cannot read the final image and infer any of it. The only way to get there is to sit with a lot of outputs, name what failed, and write the rule down.
Most people will not do that. Most people will keep writing better adjectives.
What This Means If You’re Building
If you are using these tools seriously, the question is not how to write better prompts.
The question is what your compiler looks like.
A real compiler has a small input contract. It has a regime router. It has a constraint stack you can name. It has a parameter policy per regime. It has a repair taxonomy. It has a memory of bundles that worked.
You do not need to ship software to have one. You can write the rules down in a note. You can keep a regime table on a page. You can make a small decision flow that says, given this input, here is the specification you are going to render against.
If you do, two things change.
Quality stops being a function of how eloquently you describe the scene. It starts being a function of whether you chose the right regime, whether your constraints are consistent, and whether your repair rules work.
And iteration stops being a random walk. You start learning from every failure, because you are only changing one variable per generation.
Neither of those things happen when you are treating the prompt as a sentence to polish.
The Real Question
Most people running these tools today are still prompt writers. They are sitting inside the model, writing increasingly clever sentences, hoping the next one finally cracks the image they can already see in their head.
The operators who will build durable advantages here are doing something different.
They are sitting one level up.
They are writing the compiler.
They are keeping regimes, constraints, parameters, exclusions, and repair rules as structured assets. They are updating them every time they learn something. They are making the prompt a side-effect of a specification, rather than the thing they are trying to perfect.
A prompt is cheap. A compiler compounds.
The question is not which one you have today.
The question is which one you are quietly building.
The cover on this piece follows the same logic: the spec was compiled once, then rendered in Grok rather than Midjourney because that renderer matched the regime better.
If you are building one: what regimes do you have? What is in your repair taxonomy? Which constraint did you have to learn the hard way? I’d genuinely like to read what other people have ended up with — leave it in the comments.
If a single argument here changed what you were about to trust, the highest-leverage move is to subscribe on Substack. One piece a week, no filler.